The client operated multiple cloud environments across different customers, each with varying service criticality and operational requirements.
Manual monitoring, inconsistent alerting, and unclear ownership led to delayed responses, increased operational risk, and alert fatigue among on‑call engineers.
1. REALITY GAP MAPPING
We assessed the existing monitoring, alerting, and incident management workflows to establish a clear view of the current state. This is what we discovered:
Inconsistent alert severity definitions
Manual triage and escalation
Excessive alert noise
Limited traceability between monitoring tools and ITSM
“Understand the gap. Redesign the flow.”
2. PROCESS RE‑ENGINEERING
Based on the identified gaps, we redesigned the alert‑to‑incident lifecycle to ensure consistent prioritisation, clear escalation paths, and automation readiness:
Priority‑driven escalation logic
Clear separation of critical vs non‑critical events
Removal of manual decision points
3. SERVICE DESK ACCELERATION
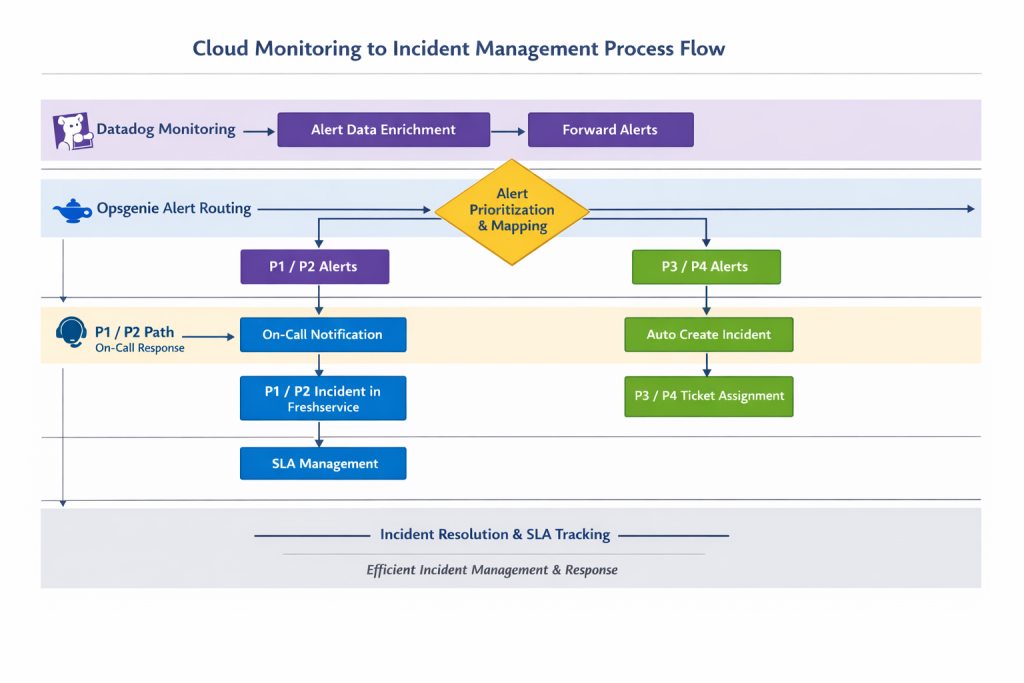
Cloud Monitoring (DataDog)
We configured Datadog to monitor each client environment with strict separation and contextual tagging:
Client and environment tagging
Infrastructure and application monitors
Anomaly detection for early warning
Alert Intake & Priority Mapping (Opsgenie)
Opsgenie served as the central alert intelligence layer, classifying alerts consistently into P1–P4 based on impact and business rules. We used APIs to link DataDog to Opsgenie.
Cloud Monitoring (DataDog)
P1 / P2 alerts notified the on‑call engineer via rotation schedules
Alerts required acknowledgement to establish ownership
Freshservice incidents were created automatically with correct priority and assignment
4. Operational Enablement
To ensure long‑term success, we embedded clear ownership models and operational standards into day‑to‑day operations:
Defined escalation and ownership models
Reduced dependency on individual knowledge
Predictable, repeatable operational workflows
Quarterly dry runs to continuously test the processes.
Creation of KPA to review and measure performance.
5. RESULTS & BUSINESS IMPACT
Operational
Faster response to critical incidents
Reduced alert fatigue
Clear accountability
ITSM
Automated incident creation
Improved SLA tracking
Better reporting and auditability
Business
Scalable across multiple clients
Improved service reliability
Reduced operational risk
6. Summary
By applying a structured ITSM improvement approach and integrating Datadog, Opsgenie, and Freshservice, the client achieved a low‑noise, production‑ready monitoring and incident management capability.
The solution aligned operational processes, tooling, and ownership models to business needs, enabling faster response, clearer accountability, and sustainable service performance across multiple environments.
See How This Approach Works for You
Start with a structured ITSM evaluation covering assessment, optimisation, and enablement.